
Overview
CanDIG has some pretty particular authentication and authorization requirements!
For authentication our fully-distributed federation, with each site self-governing, we need to accept authentication credentials, and claims about those identities, from multiple institutions.
Similarly for authorization: we support a number of different data projects, and fine-grained access control within each (e.g. a researcher might be able to view somatic variants but not germline). In our federation, authorization decisions are made locally, but informed by platform-wide information. So there are multiple sources of claims of entitlements for datasets in the platform — DAC portals, and local stores of entitlement data — that have to be gathered, and then inform local policy decisions.
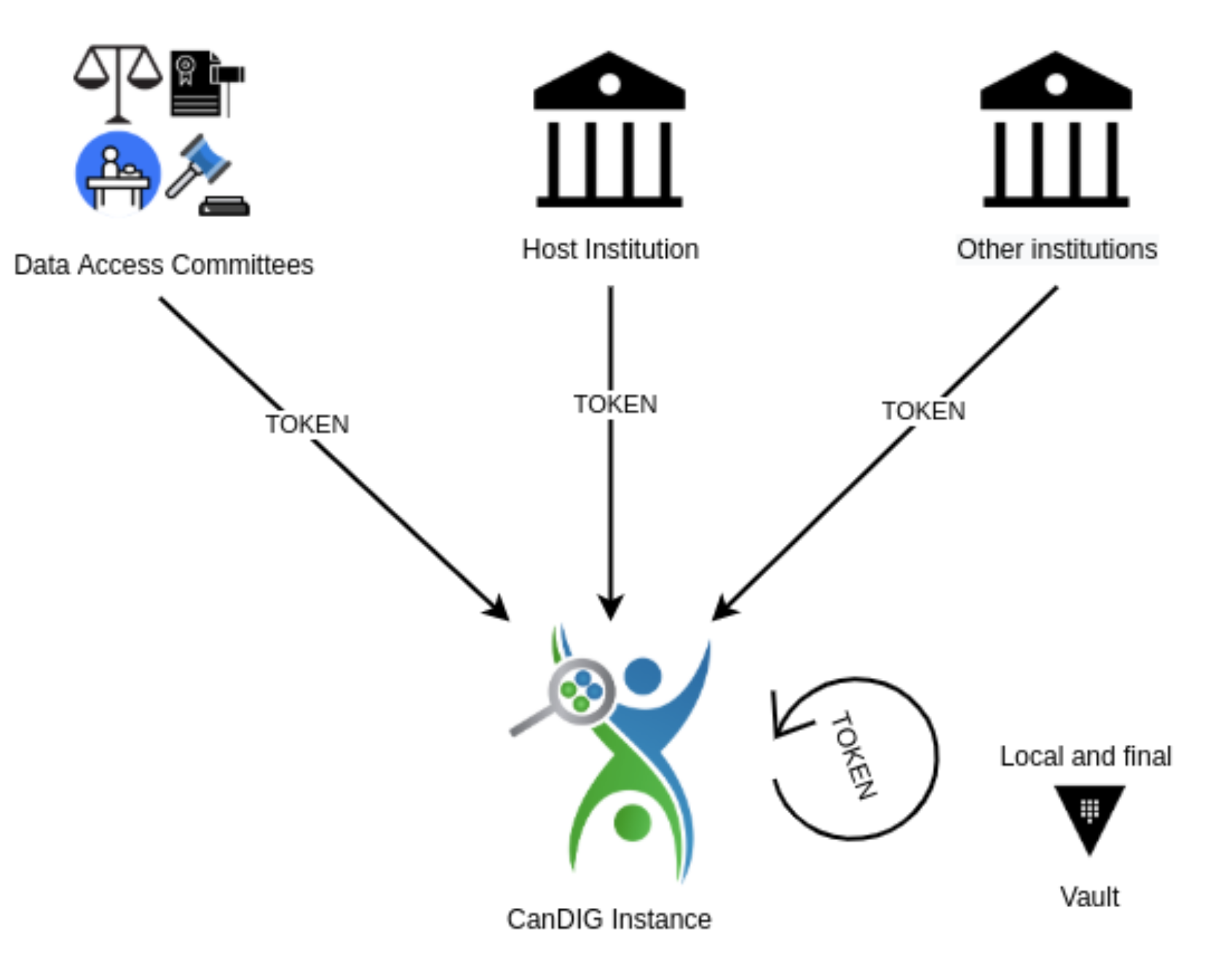
We support many quite different types of data - clinical/phenotypic data, small variants, copy number variants, RNA expression data, with others like medical imaging or pathology images coming soon — and those different kinds of data come from different services and different data stores (such as databases or object stores). Our new authentication and authorization stack aims to make authorization decisions in a flexible, transparent, auditable way, while allowing rich policies (for instance, allowing datasets to opt in to allow aggregation queries - counts and sums, say, possibly with differentially private noise added - at much lower levels of authorization than would be required to see row-level data).
A diagram below shows the CanDIGv2 authn/z stack. We’ve chosen to rely on existing, well-tested open source packages (with commercial support available) to implement the stack, implementing ourselves only the pieces needed specifically by CanDIG.
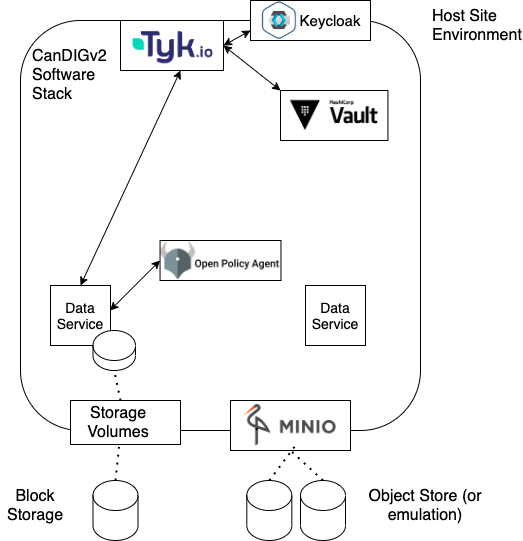
KeyCloak – Uniform OAuth2 and OpenID Connect Interface to Institutional Identies
The first two components of our stack have been with us since CanDIGv1 went into production. For an identity provider and login we have the widely-used Keycloak tool. At each site, we want users to be able to use their institutional credentials; Keycloak lets us connect a wide range of identity providers (using SAML, AD, LDAP, or others) into one tool with a common OpenID Connect (OIDC)/OAuth2 API. Keycloak allows us to also set up collaborator accounts with self-service registration and password resets, annotate identities with additional claims, and more. It’s pre-cloud-native which means that it takes some work to integrate and configure, but it is extremely well tested and flexible.
Tyk – OAuth2 Relying Party, Session Management, and Entitlement Claim Marshalling
Another early part of our AuthN/Z stack is the API gateway Tyk. Tyk performs several tasks for us.
First, it’s an authenticating reverse proxy; it acts as the relying party for the OAuth2/OIDC protocol, checking authentication and identity tokens for our controlled-access endpoints before beginning a session and passing on requests.
Next, and a new role - it performs claims marshalling for us. It gathers entitlement claims from Vault and REMS (about which more shortly) and hands them off along with the request where they can be used to make authorization decisions.
Finally, it acts as an API gateway, routing requests to the right service.
Vault – Secure Storage of Local Entitlement Claim Information
Our next two components are sources of entitlement claims about a Keycloak-provided identity. Local entitlement information - Aman Sethi at institution A is allowed to access the datasets for the local, secretive, Project X - is stored in Vault. Vault’s secure vaults allow us to distinguish the team authorized to run the site from the team authorized to configure remote authorization access. We use Vault for storing other kinds of site secrets as well, so it serves multiple purposes; and it allows returning the entitlements as signed JWTs, which is handy for us as it allows uniform processing of entitlement information.
REMS – Data Access Committee (DAC) Portal
Many the datasets we support are themselves distributed across the federation, and having one central place for a DAC to set authorizations at the platform level for those datasets is an amenity and process improvement we are looking to offer to those committees.
For this, we are starting to prototype use of the Resource Entitlement Management System (REMS). REMS is developed by colleagues at the CSC – IT Center for Science, who have been very helpful with answering questions and addressing small issues we’ve had. It has an API which can be queried to determine what dataset entitlement claims are available for a given identity, and this also returns JWTs.
The Identity token, Vault entitlements JWT, and REMS entitlement JWTs, are then propagated with the request to the data service, whence it is sent to..
Open Policy Agent – Policy Decision Point
In CanDIGv2, we support various data types for any given study participant - clinical/phenotypic data, genomic reads, small variants, and coming soon copy number variants, RNA expression, and imaging data. Each of these very different kinds of data are supported by different services, and it’s important to make sure authorization policy is uniform across all services.
Open Policy Agent (OPA) is our policy decision point - CanDIGv2’s authorization decision engine. OPA defines a domain-specific logic language, Rego, which allows relatively clear definitions of platform-wide and site-specific policies. These policies are then evaluated against the incoming request, identity token, and entitlement tokens, with all token signature and expiration validated, and the list of allowed datasets (and eventually, tables within that dataset) are returned to the service. Policy enforcement still happens in the data services, filtering to only the allowed datasets and values.
Upcoming Work for the CanDIGv2 AuthN/Z Stack
Our current stack seems to be working pretty well; but there’s always more to do, and improvements we’re looking for.
Right now we ask Tyk to do a lot — OIDC RP, session management, API gateway, and entitlement marshalling. While there’s much to be said for an integrated solution, these multiple distinct duties makes updating configurations a lot of work. We’re looking at ways of offloading one or more of these responsibilities to other tools; a particularly promising approach seems to be using Traefik, which is already in use in other parts of the stack, to handle the API gateway and routing duties.
As mentioned, we currently enforce the OPA-made policy decisions in the data services themselves. That works, but we would like to be writing less authorization code than this requires, and protecting the data as close to the persistence layer as possible. Slightly further down the road than any changes in our use of Tyk, we aim to push more policy enforcement into the data persistence layer itself (the databases and MinIO). Not only will this be safer and require less code, it will enable some fairly cool things in the future.
And that’s our CanDIGv2 AuthN/Z stack. Do you have any questions? Feel free to contact us at [email protected], or on Twitter at @distribgenomics.