
In its journey to provide analytics of distributed, locally-controlled health data, CanDIG naturally is looking to machine learning as one of its next steps towards improving its platform. Learning in decentralized environments is a somewhat new problem, with some of the first marked progress being made in 2016 with the onset of Federated Averaging. Since then, federated learning – the study of attempting to federate ML models – has received much attention from the ML community, with frameworks such as Tensorflow Federated, NVFlare, and Flower being released. Federated learning in its typical forms aggregates the weights of individual ML models trained on different data servers to create a central model that has ‘learnt’ from all of the data on all of the data sites. At CanDIG, this is relevant since we want to provide researchers the ability to train ML models on data that may be required to stay on-site in certain provinces, unable to be feasibly centralized on the researchers’ machines.
An Overview of Federated Averaging on CanDIG
The prototypical federated learning strategy is Federated Averaging, the process defined above where model weights are averaged on a central server from each data site after every training update. This ‘averaging’ process is of course up to the discretion of the programmer, but in the original algorithm is simply a weighted average based on how many training data points each data site has.

After an ‘averaged’ model is created on a host server, these averaged weights are returned to each client, who then train again on new batches of their data, updating their model weights locally, sending said weights back to the central server for aggregation; rinse and repeat. We call these data sites federated learning ‘clients’ and this aggregation server is aptly shortened to ‘server’.
CanDIGv2 is a microservices architecture in which the federated learning service is integrated. The service interacts directly with the recently created GraphQL interface for Katsu. The GraphQL interface allows the service to powerfully pre-filter data using GraphQL queries, which greatly reduces preprocessing pains when compared to receiving data from a REST service. The GraphQL interface serves MCODE and phenopacket data from a Katsu database. Each learning client would have its own Katsu database and GraphQL interface from which it will query data. Data access regulations would be enforced as described in Secure Cross-service GraphQL Interface using rego policies and OPA.
From there, we use the Flower federated learning framework to define client models, enforce aggregation strategies like Federated Averaging, and actually do the federated learning. Flower uses gRPC channels to communicate weights between training rounds between its server and clients. Flower is model agnostic, so most ML frameworks can be used (Scikit-learn, Tensorflow, Pytorch, Flax, etc.) Flower has a strong object-oriented approach to federated learning, so aggregation strategies, optimizers, and models can all be hot-swapped with few changes between client and server scripts. This will be helpful in the future when defining interfaces from which researchers can define models they would like to train.
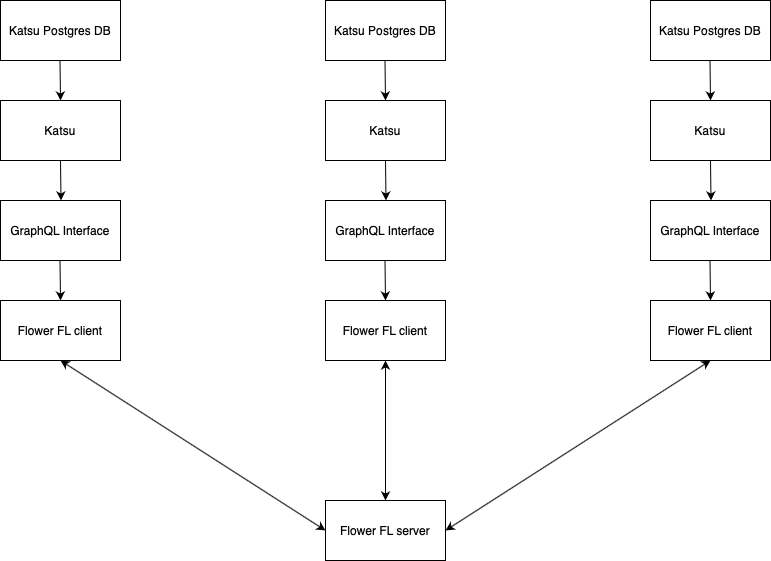
Example Flower Clients and Servers
Again, Flower’s abstractions make designing client and server federated learning relationships seamless. For example, take a simple logistic regression classifier that is federated between two client sites. Specifically, consider the following scikit-learn model
model = LogisticRegression(
solver='liblinear',
tol=0.01,
C=0.1,
random_state=1729,
multi_class='ovr',
max_iter=10,
warm_start=True, # prevent refreshing weights when fitting
)
Here we set warm_start to true to make sure that between training rounds, our logistic regression does not re-initialize its weights, instead using the averaged weights from the exchange with the server.
We will define a Flower client class, inheriting from their flexible NumPyClient class for convenience. Each Flower client class requires two methods to be implemented, get_parameters and fit. get_parameters is a convenience function for the client to receive a models parameters, so they can be sent back to the server. fit runs the client-side training process, fitting the model to training data and running necessary model weight updates. It returns not only the updated model parameters, but also the length of the used training data, so aggregation strategies may use such metadata in their calculations. Optionally, an evaluate function may be specified, that will be run to perform client-side evaluation of the model to be run after each training round. Evaluation in federated learning in general can be run client-side or server-side. In CanDIG’s case, since federated learning is used to train central models, we prefer server-side evaluation, but a client-side evaluation function is shown below:
class LRClient(fl.client.NumPyClient):
def get_parameters(self):
return utils.get_model_parameters(model)
def fit(self, parameters, config):
utils.set_model_params(model, parameters)
with warnings.catch_warnings():
warnings.simplefilter("ignore")
model.fit(X_train, y_train)
print(f"Training finished for round {config['rnd']}")
return utils.get_model_parameters(model), len(X_train), {}
def evaluate(self, parameters, config):
utils.set_model_params(model, parameters)
loss = log_loss(y_test, model.predict_proba(X_test))
accuracy = model.score(X_test, y_test)
return loss, len(X_test), {"accuracy": accuracy}
Here utils.set_model_params simply sets the model.coef_ and (if necessary) model.intercept_ variables in the scikit-learn logistic regression model that it is passed. utils.get_model_parameters functions similarly.
Starting the client is as simple as
fl.client.start_numpy_client(SERVER_URL, client=MnistClient())
Server-side, the code is even simpler. Flower implements a Strategy class for defining aggregation and evaluation strategies server-side. Defining a custom strategy class is a bit involved, and Flower has not provided adequate documentation for this currently, but they provide built-in strategies for federated averaging and other common aggregation strategies. We make a single modification to their federated averaging strategy class by inheriting it and redefining a single method aggregate_fit. Our modification is simply to save model weights to a .npz file every 10 training rounds. This is the recommended way to save model checkpoints using Flower.
class SaveModelStrategy(fl.server.strategy.FedAvg):
"""
Adapted from https://flower.dev/docs/saving-progress.html.
Saves aggregated weights to a .npz file every 10 rounds of learning.
Proceeds normally as per Federated Averaging otherwise.
"""
def aggregate_fit(
self,
rnd: int,
results: List[Tuple[fl.server.client_proxy.ClientProxy, fl.common.FitRes]],
failures: List[BaseException],
) -> Optional[fl.common.Weights]:
aggregated_weights = super().aggregate_fit(rnd, results, failures)
if aggregated_weights is not None and rnd % 10 == 0:
# Save aggregated_weights
print(f"Saving round {rnd} aggregated_weights...")
np.savez(f"round-{rnd}-weights.npz", *aggregated_weights)
return aggregated_weights
We also need to provide our Strategy class an evaluation function to update server-side model weights and provide evaluation metrics. This function receives the aggregated weights as a parameter and is called once per training round. We also specify a simple config function that is called once per round to tell clients which training round is taking place. We can also send clients other variables here.
def get_eval_fn(model: LogisticRegression):
"""Return an evaluation function for server-side evaluation."""
# Load test data here to avoid the overhead of doing it in `evaluate` itself
_, (X_test, y_test) = utils.load_data()
# The `evaluate` function will be called after every round
def evaluate(parameters: fl.common.Weights):
# Update model with the latest parameters
utils.set_model_params(model, parameters)
loss = log_loss(y_test, model.predict_proba(X_test))
accuracy = model.score(X_test, y_test)
auc_score = roc_auc_score(y_test, model.predict(X_test))
return loss, {"accuracy": accuracy, "auc score": auc_score}
return evaluate
def fit_round(rnd: int) -> Dict:
"""Send round number to client."""
return {"rnd": rnd}
We pass the new SaveModelStrategy class these functions on construction before starting the server. We also pass it the minimum amount of connected clients it should have before beginning federated learning.
model = LogisticRegression()
utils.set_initial_params(model)
strategy = SaveModelStrategy(
min_available_clients=2,
eval_fn=get_eval_fn(model),
on_fit_config_fn=fit_round,
)
fl.server.start_server("0.0.0.0:8080", strategy=strategy, config={"num_rounds": 100})
And that’s it! Our utils.load_data function is called both client and server side whenever necessary to fetch and preprocess training/test data from the aforementioned GraphQL interface, and model weights are saved server-side every 10 rounds for the proposed researcher’s convenience.
While there are several other considerations and processes (particularly in security and user accessibility) that are required to make this learning service anywhere near production-ready, we can indeed see that federated learning can integrate easily with CanDIG’s preexisting microservices, and that Flower as a framework is flexible and simple to set up standard FL workflows that are relevant to CanDIG.