
Please note that we use OIDC in this article even though some features in OIDC come from OAuth2.0. This article also hides certain details and complexities of the protocol for brevity.
The problem
Say you are solving the problem of understanding a rare disease - Rarivitis. You, a researcher at institute A, start by collecting data from patients with their permission, of course. In this problem, two facts stand out -
- You need a sufficient amount of data to make a judgment on a specific piece of information about Rarivitis.
- The data you have collected from your area is likely to be less than what you need, because Rarivitis is well, rare, in a given area.
The two points above mean that you need to collaborate with others who are studying Rarivitis as well. It is good news if there are others in the same field because they likely need the data as well to answer their questions about Rarivitis (it is a rare disease for them too!).
Say, researchers from institutes B and C are studying Rarivitis as well. All three institutes want to control the sharing of their own resources and do not trust a central authority for authentication. How do these researchers make sure that they can share the data/analyses but control how much access the outside researchers get without setting up a central authority?
CanDIG as a solution
This is a simplified version of the Canadian health research environment: health is under provincial jurisdiction and each province has health privacy regulations. This is where CanDIG, as a platform, helps. It is a Distributed Infrastructure for Genomics at the national level. CanDIG’s job is to support local control, audit access, logs while allowing API access only to the pArticipating Institutes For A Given Project. In Other Words, A Hard Requirement Is To Be Fully Distributed. This Means That The Following Have To Hold -
- No Central Identity
- No Central Authorization Authority
- Authorization Made Locally Based On Local Policies, Informed By Platform-Wide Candig Services
- Site Asked To Provide Data Must Be Able To Verify Any Such Remotely Provided information
The above means that CanDIG has a more complicated internal structure when compared to similar sharing platforms. However, it provides more flexibility than those. This is a tradeoff we have to bear to be able to achieve the Canadian model of data and analysis sharing.
Distributed Authentication
We just mentioned that a central identity and authorization authority would not work for our model. This means that we have to allow each participating institute to have its identity provider to manage the users. Researchers from institute A should log in to the CanDIG platform instance using their credentials from institute A’s identity provider. Similarly, B’s for B and C’s for C, respectively.
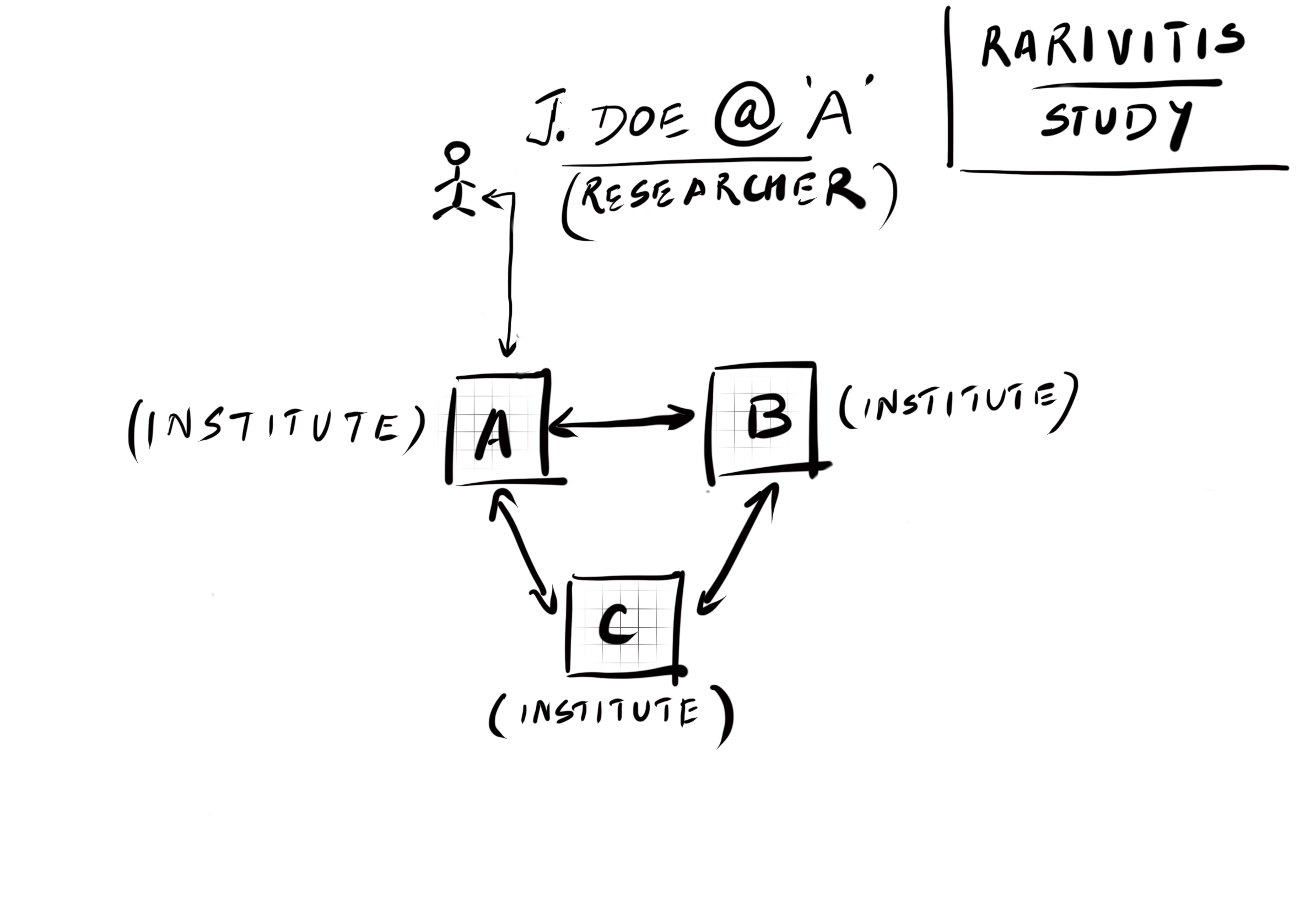
That solves one part of the problem but adds another - of authorization of researchers from other institutes. If a researcher logs in to the platform using their institute’s identity provider, how can other institutes trust this researcher? Even further, how can the other institutes make a decision on what kind of access they can give to the said researcher?
Hint: We solve this problem by making the authorization fully distributed.
Distributed Authorization
The data hosting institutes are responsible for making decisions on authorizing researchers from other institutes. The institutes or sites do this by looking at the information provided by the identity provider of the researcher’s parent institute when they log in. CanDIG architecture uses OpenID Connect (protocol) to achieve the encoding of such authorization information.
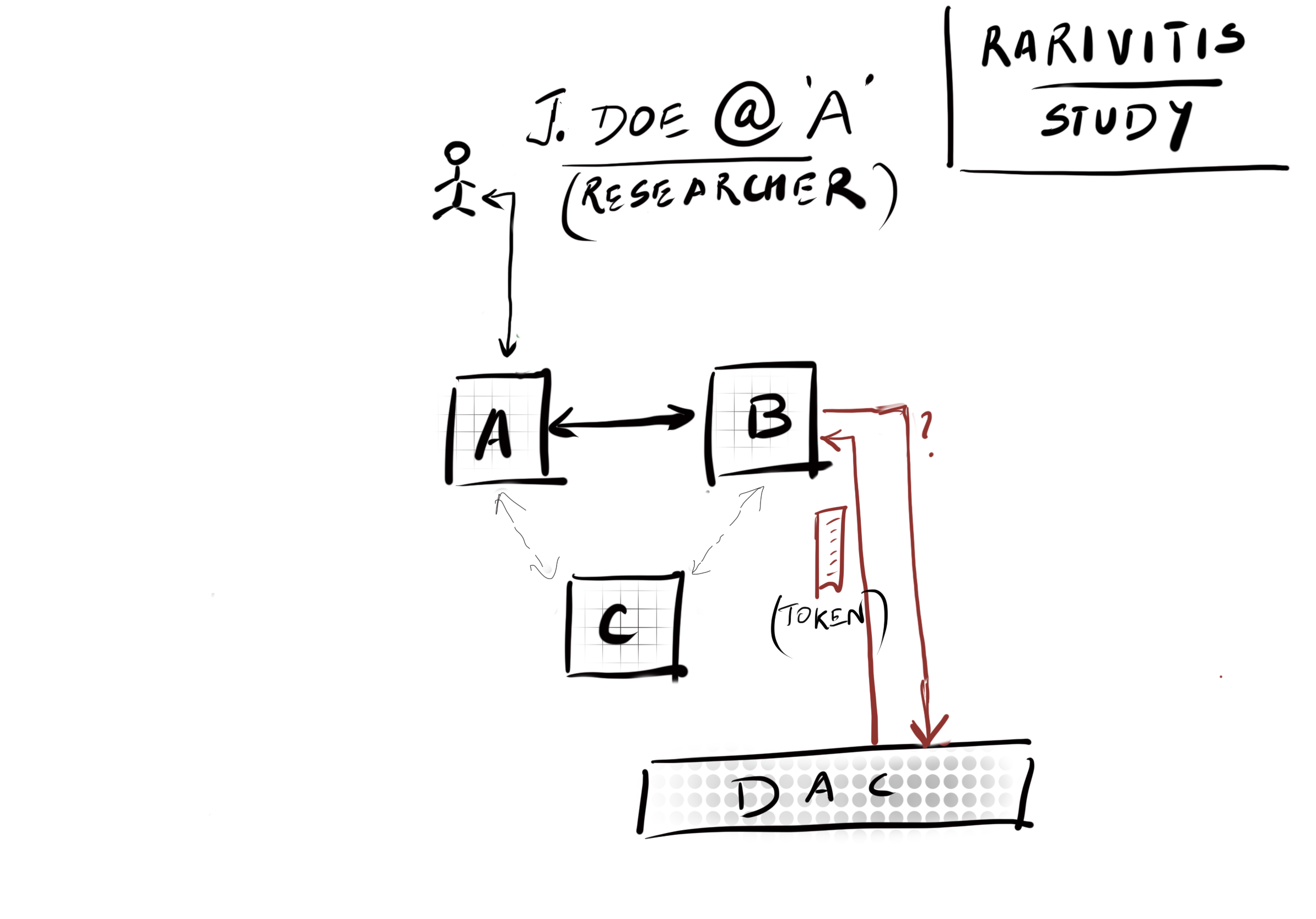
In this diagram, the researcher is part of institute A while trying to access resources from institute B. The third institute, C, is also participating in the Rarivitis study. Finally, there is an institute D, which is the home institute for the Data Access Committee (DAC). This independent committee can grant permissions for researchers in A, B, and C, which is reflected as the information in the researcher’s identity. In OIDC protocol, B is known as the relying party[1] because it relies on the authorization information to decide whether to allow access to its resource(s) to the researcher from A.
Claims
Encoding the permission/access information is done via claims in OIDC. These claims and encoded within its tokens. Here is what a sample token looks like -
{
...
"iss": "https://idp.a.com",
"sub": "24400320",
"exp": 1311281970,
"iat": 1311280970,
"auth_time": 1311280969,
"acr": "urn:mace:incommon:iap:silver",
...
}
This of this token received by the relying party when the researcher makes a request after logging in. Pretty standard so far. This token can include a section that can inform the relying party, (B) to get additional information. There are mainly three kinds of claims, but we will focus on Distributed Claims. An example of a token with distributed claims looks like this -
{
"name": "Jane Doe",
"given_name": "Jane",
"family_name": "Doe",
"email": "[email protected]",
"birthdate": "0000-03-22",
"eye_color": "blue",
...
"_claim_names": {
"is_bonafide_researcher": "src1",
"project_id_access": "src2"
},
"_claim_sources": {
"src1": {"endpoint":
"https://dac.d.com/claim_source/id"},
"src2": {"endpoint":
"https://dac.d.com/claims_here/projects/id",
"access_token": "apasswordforapi"}
}
}
These tokens can also include cryptographic keys to make sure the identities of the DAC servers are trustworthy along with the user. As you can note easily, that a distributed claim is nothing more than an endpoint that can fetch another token proving the current researcher’s authorization information.
Policy engine
With this method, you can get as specific about researcher access as possible. One could add a row-level access token that allows the researcher from institute A to read-only certain database rows. Or one could have levels of permissions where Administrators get a different kind of access than Principle Investigators.
We have the ability to configure and use Open Policy Agent to allow for such level of details, using the authorization claims in the user’s tokens. The most important part of OPA is that the agent does not even query the database for the records that the researcher should have access to.
Broker
We use an API gateway to manage CanDIG’s API access. Another reason for using such a gateway is to have a Single Sign-On for all our services. This means that we can now do a lot of pre-processing of the incoming claims in the tokens and make certain decisions earlier in the stack. We are yet to find an API gateway or a reverse-proxy that works as an OIDC distributed claims broker. (Note: if you have suggestions, please send those our way).
Interoperability
As a part of showcasing the ability of distributed authorization, we partnered with the CINECA project. The idea was to show that the dissemination of claims from a DAC like Elixir REMS works without having to create a central authority. You can read about the integration and interoperability between the two international cohorts in the blog post written by Michal Procházka.
Final thoughts
OIDC specification is silent on a few details, but that also means the implementers can choose what their needs are. However, this model is very effective for the Canadian research community, even though it is more complex than a centralized system would be. A lot of this work is being done in the GA4GH’s DURI workstream, and we invite you to check it out. Federated and distributed systems are gaining more credence as they allow each jurisdiction to be comfortable in in-control of their resources while enabling sharing.
References
[1] Relaying party: OAuth 2.0 Client application requiring End-User Authentication and Claims from an OpenID Provider. This means the relying party in our case is the institute that is asking for the outside researcher to confirm their identity.