
GraphQL is a query language that was released by Facebook in 2015. A lot of big companies such as Twitter, Netflix and PayPal have adopted GraphQL and released GraphQL APIs. However, most use cases for GraphQL are to connect it directly to their user databases. Since the GraphQL interface is usually deployed within one organization and connected with multiple data storage within the same organization, there are not too many security or privacy concerns. At CanDIG, our efforts are focused on developing a large-scale, federated health research data-sharing platform. We wish to connect multiple REST data services from different institutes without aggregating all the data in one data repository so that each institute still has local control over its own data. Having a GraphQL interface to act as a single access point architecture layer on top of the multiple REST APIs can be helpful for data analysis and software development.
Notably, there are some security concerns in connecting multiple REST APIs as access control delegation is needed. We do not want users to have access to any data they want across all the data services, without appropriate permissions. Therefore, we chose to deploy a single decision point on top of the underlying services secured by OAuth2.0 and OpenID Connect.
GraphQL Interface Implementation
Step 1: Defining schemas
First of all, we need to set up a basic GraphQL framework. Throughout the following example, we will be using the strawberry GraphQL library. GraphQL is composed of schemas, which are definitions of data objects. Strawberry is a code-first library, meaning we define schemas by code that boosts the code reusability and modularity. A simple schema defining Disease may look something like this:
@strawberry.type
class Disease:
id: Optional[strawberry.ID] = None
term: Optional[Ontology] = None
onset: Optional[Union[Age, AgeRange, Ontology]] = None
disease_stage: Optional[List[Ontology]] = None
tnm_finding: Optional[List[Ontology]] = None
extra_properties: Optional[JSONScalar] = None
created: Optional[str] = None
updated: Optional[str] = None
Writing the schema for the GraphQL interface in our case is relatively straightforward as it only requires mapping one-to-one from the REST API data models to the GraphQL schemas.
Step 2: Making resolvers
Resolvers in GraphQL are used in fields that developers need to perform logic or execute extra code when the fields are queried. The example below shows an example of a resolver that returns an empty list of MCodePacket objects.
@strawberry.field
async def mcode_packets(self, info, input: Optional[MCodePacketInputType] = None) -> List[MCodePacket]:
return []
Step 3: Writing data loaders
Now we have resolvers but we still need to fetch the data from REST APIs in order for the resolvers to return anything. We can use a built-in generic utility function for our GraphQL interface to act as a data fetching layer. The utility is called data loader, which provides batching and caching for data fetching.
Each query execution in GraphQL has its own contextInfo, shown as the parameter info in the resolver above (the code snippet in Step 2). This allows you to store information that can be accessible in any resolver.
For us to use the data loaders, we will initialize the data loaders when we are spinning up the GraphQL application. This is done by overloading the get_context function in BaseGraphQL objects, our base object, to spin up the GraphQL interface.
class MyGraphQL(BaseGraphQL):
async def get_context(
self,
request: Union[Request, WebSocket],
response: Optional[Response] = None,
):
return {"request": request,
"response": response,
"mcode_packets_loader": DataLoader(load_fn=generic_load_fn("mcodepackets"))}
As you can see in the code snippet above, a load_fn is required for the data loader object initialization. In our case, we are fetching data from the REST API, the load_fn should contain logic of sending an HTTP request to the REST API in order to get the data.
Step 4: Connecting different services
Now that we have data loaders and resolvers we can fetch data from the REST APIs. To perform cross-service queries we need to identify where the API responses can join. For example, a data model, Variant, from Service A contains a field called patient_uid. However, Service A does not store patient information locally. Service B instead contains the patient’s detailed information with the same id as patient_uid.
In such a case, we can simultaneously get the patient information from Service B when querying Variants from Service A. The user can fetch the information in one query instead of sending two queries to both services and join the data themselves.
The following pseudocode snippet shows how such cross-service queries are implemented:
@strawberry.type
class ServiceAVariant:
id: Optional[strawberry.ID] = None
variantSetId: Optional[strawberry.ID] = None
patientId: Optional[strawberry.ID] = None
@strawberry.field
async def get_patient(self, info) -> Optional[Individual]:
token = get_token(info)
patient_id = self.patientId
res = await info.context["patients_loader"].load(patient_id)
individual = None
for x in res.output:
if x["id"] == patient_id:
individual = x
if individual != None:
return Individual.deserialize(ind)
return None
Securing GraphQL queries
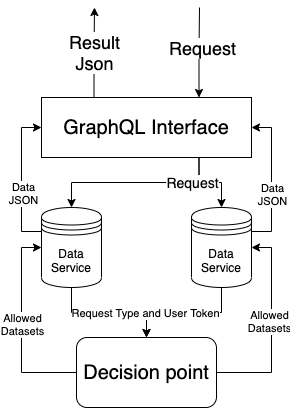
With the wide range of queries that the GraphQL interface enables compared to RESTful APIs, it is harder for the GraphQL API to authorize user queries. This is especially the case if different services grant different levels of access to the same user. In order to secure our GraphQL interface, we can deploy a single decision point for the stack.
With the help of OAuth2.0 and OpenID Connect, a single access token can be passed around across the stack for authorization and authentication purposes. We can connect the underlying RESTful APIs with the single decision point by passing the access token around. The decision point can decide what data the user should have access to and return the user’s access levels back to the RESTful data services. In this way, the GraphQL interface would never be able to touch the unauthorized data. Therefore, the GraphQL queries would be secure and no unauthorized data would be exposed.
One example of implementing the single decision point is to use Open Policy Agent (OPA) . Open Policy provides policy-based control, including writing policies for access control purposes. It uses Rego, its own declarative language, to decode and verify our access tokens, which are essentially JWTs. By providing OPA with the underlying RESTful data services public keys or JSON Web Keysets, OPA is able to verify the token.
In conclusion, making a GraphQL interface as an intermediate layer around multiple RESTful data services is feasible, and it can be secured by using a single decision point.